Flume的简单介绍和使用.md
一、概述
Flume是由cloudera开发的实时日志收集系统
Flume核心概念是由一个叫做Agent(代理节点)的java进程运行在日志收集节点
Flume在0.94.0版本以前(包含0.94.0版本)称为Cloudera Flume OG,由于0.94.0版本以前存在各种缺陷,因此不得不重新设计Flume并更名为Apache Flume NG(1.0.0开始)
相对于FlumeOG,Flume NG有如下特点
只有一种角色节点:代理节点agent
没有collector、master节点,这是最核心的变化.
去除逻辑节点和物理节点的概念和内容
agent节点的组成发生变化,由source 、sink、channel三个组件组成
二、Flume软件架构
要理解Flume,就首先理解它的架构,下面看下,官网的一张拓扑图:
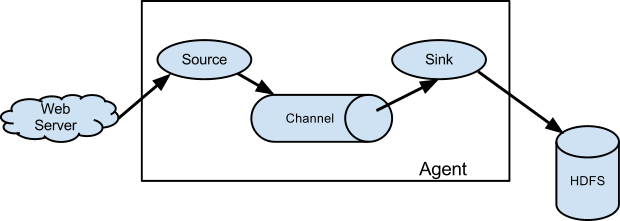
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成。
名词解释
Source:泛指所有的日志收集源,可以是web页面,log文件,数据库,端口,卡口信息等
Channel:提供中转的临时存储区,可以是本地文件,redis,kakfa,数据库,内存等
Sink:指日志最终落地的存储区,可以是数据库,HDFS,Hbase,Hive,本地文件等
Agent:指上面三者组合后的一个完整的数据收集代理,有了这个代理,我们把它安装任何机器上进行收集日志,当然前提是这个Agent符合这个机器上的业务。
三、安装运行
Flume 运行系统要求1.6以上的Java 运行环境,从oracle网站下载JDK 安装包,解压安装。
Flume 二进制安装包可以从官网下载,解压后可以直接使用。
解压并修改配置文件:
#Name the components on this agent
a1.sources= r1
a1.sinks= k1
a1.channels= c1
#Describe/configure the source
a1.sources.r1.type= netcat
a1.sources.r1.bind= localhost
a1.sources.r1.port= 44444
#Describe the sink
a1.sinks.k1.type= logger
#Use a channel which buffers events in memory
a1.channels.c1.type= memory
a1.channels.c1.capacity= 1000
a1.channels.c1.transactionCapacity= 100
#Bind the source and sink to the channel
a1.sources.r1.channels= c1
a1.sinks.k1.channel= c1然后使用以下命令启动flume
./bin/flume-ng agent -c conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console注意:flume启动参数,-c/--conf 后跟配置目录,-f/--conf-file 后跟具体的配置文件,-n/--name 指定agent的名称。
四、Flume调试
启动后的flume进程是一个在前台运行的程序,会输出很多的调试信息,最后会停留在等待状态,等待信息输入。
接下来,我们开启另外一个终端,telnet 本机 44444端口,然后输入一些字符,就可以在flume程序调试界面看到输入的字符了。
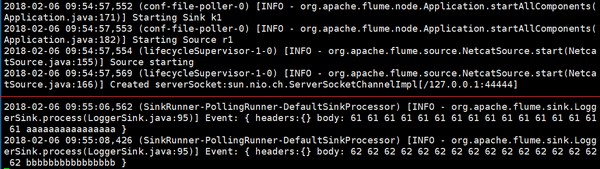
注意:Flume自带的Logger Sink默认限制了event的大小为16字节,多余的部分丢弃掉了。
五、参考资料
http://flume.apache.org/FlumeUserGuide.html
转载请注明:IPCPU-网络之路 » Flume的简单介绍和使用