prometheus和node_exporter中的磁盘监控.md
对于磁盘问题,我们主要关注以下几个指标:
磁盘空间使用率、磁盘inode使用率(df -h和df -i命令)
磁盘读写次数IOPS (iostat中的r/s、w/s)
磁盘读写带宽 (iostat中的rkB/s、wkB/s)
磁盘IO利用率%util (iostat中的%util)
磁盘队列数 (iostat中的avgqu-sz)
磁盘读写的延迟时间 (iostat中的r_await、w_await)

这些指标都可以在node_exporter中找到对于的线索。
1. 磁盘空间使用率和磁盘inode使用率
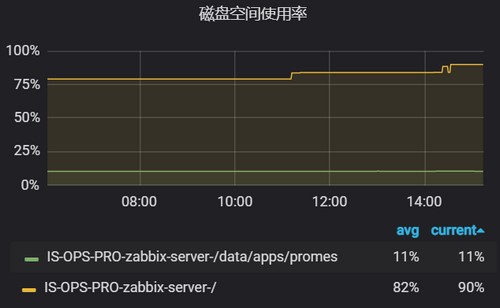
磁盘空间使用率
100 - ((node_filesystem_avail_bytes{instance=~"$hostname",fstype=~"ext4|xfs"} * 100) / node_filesystem_size_bytes{instance=~"$hostname",fstype=~"ext4|xfs"})
磁盘inode使用率
100 -node_filesystem_files_free{instance=~"$hostname",fstype=~"ext4|xfs"}/node_filesystem_files{instance=~"$hostname",fstype=~"ext4|xfs"} * 1002. 磁盘IOPS
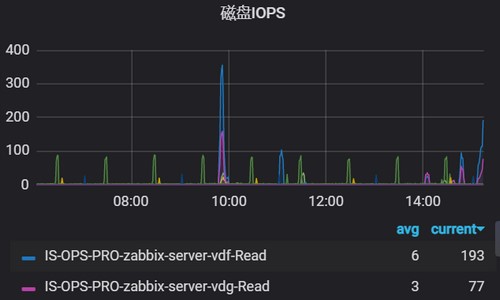
读IOPS
rate(node_disk_reads_completed_total{instance=~"$hostname",device=~"[a-z]*[a-z]"}[5m])
写IOPS
rate(node_disk_writes_completed_total{instance=~"$hostname",device=~"[a-z]*[a-z]"}[5m])3. 磁盘IO利用率%util
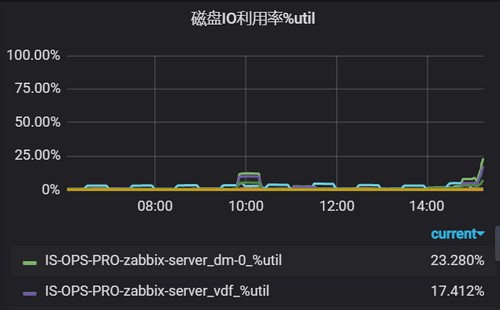
磁盘IO利用率(iostat中的%util,取值范围[0-1])
rate(node_disk_io_time_seconds_total{instance=~"$hostname"}[5m]) util%到达100%并不一定会存在磁盘瓶颈,因为磁盘设备可以并发(fio中的多队列),判断磁盘瓶颈要根据util%、IO队列数、读写延迟的历史趋势来判断。没有办法,因为磁盘厂商也没给出相关参考。
4. 磁盘设备平均IO队列数
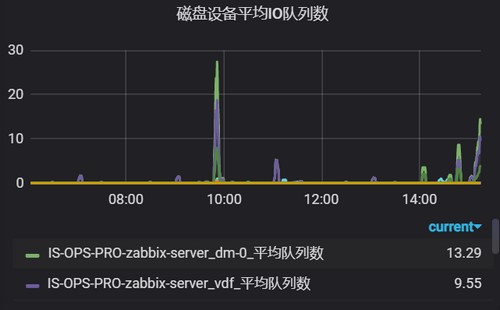
rate(node_disk_io_time_weighted_seconds_total{instance=~"$hostname"}[5m])5. 磁盘设备读写延迟
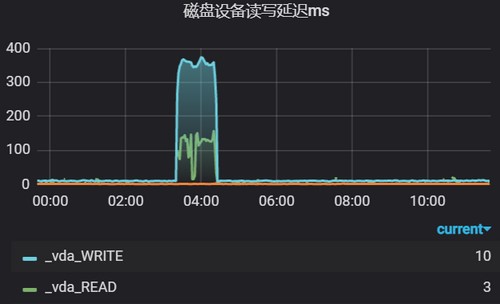
读延迟(ms)
rate(node_disk_read_time_seconds_total{instance=~"$hostname"}[5m]) / rate(node_disk_reads_completed_total{instance=~"$hostname"}[5m]) * 1000
写延迟(ms)
rate(node_disk_write_time_seconds_total{instance=~"$hostname"}[5m]) / rate(node_disk_writes_completed_total{instance=~"$hostname"}[5m]) * 1000这个值的单位是秒, 不太好看,乘以1000可以换算成毫秒ms。这个值与设备有关,本地盘、网络盘、SSD磁盘的读写延迟级别不一。
参考资料
https://www.robustperception.io/mapping-iostat-to-the-node-exporters-node_disk_-metrics
https://brian-candler.medium.com/interpreting-prometheus-metrics-for-linux-disk-i-o-utilization-4db53dfedcfc
https://devconnected.com/monitoring-disk-i-o-on-linux-with-the-node-exporter/