etcd简介、架构.md
一、etcd简介
etcd 是 CoreOS 团队于 2013 年 6 月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库,基于 Go 语言实现。官方描述:
etcd is a distributed, consistent key-value store for shared configuration and service discovery.
etcd是一个分布式的,一致的 key-value 存储,主要用途是共享配置和服务发现。
二、Ectd架构
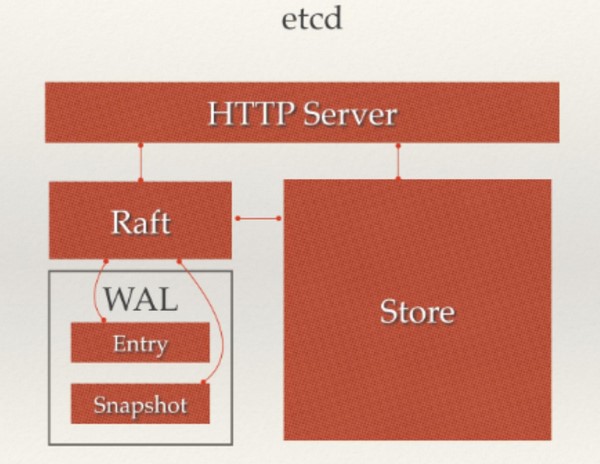
etcd 主要分为四个部分。
HTTP Server
用于处理用户发送的 API 请求以及其它 etcd 节点的同步与心跳信息请求。
Store
用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
Raft
Raft 强一致性算法的具体实现,是 etcd 的核心。
WAL
Write Ahead Log(预写式日志),是 etcd 的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd 就通过 WAL 进行持久化存储。WAL 中, 所有的数据提交前都会事先记录日志。Snapshot 是为了防止数据过多而进行的状态快照;Entry 表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务处理,如果涉及到节点的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同步给别的 etcd节点以确认数据提交,最后进行数据的提交,再次同步。
三、etcd工作原理(Raft协议)
etcd使用Raft协议来维护集群内各个节点状态的一致性。简单说,etcd集群是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过Raft协议保证每个节点维护的数据是一致的。
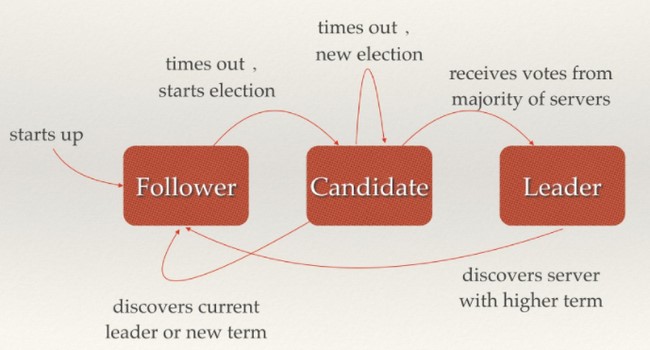
如上图所示,每个etcd节点都维护了一个状态机,并且,任意时刻至多存在一个有效的主节点。主节点处理所有来自客户端写操作,通过Raft协议保证写操作对状态机的改动会可靠的同步到其他节点。
etcd工作原理核心部分在于Raft协议。本节接下来将简要介绍Raft协议,
Raft协议正如论文所述,确实方便理解。主要分为三个部分:选主,日志复制,安全性。
3.1 Raft协议-选主
Raft协议是用于维护一组服务节点数据一致性的协议。这一组服务节点构成一个集群,并且有一个主节点来对外提供服务。当集群初始化,或者主节点挂掉后,面临一个选主问题。集群中每个节点,任意时刻处于Leader, Follower, Candidate这三个角色之一。选举特点如下:
当集群初始化时候,每个节点都是Follower角色;
集群中存在至多1个有效的主节点,通过心跳与其他节点同步数据;
当Follower在一定时间内没有收到来自主节点的心跳,会将自己角色改变为Candidate,并发起一次选主投票;当收到包括自己在内超过半数节点赞成后,选举成功;当收到票数不足半数选举失败,或者选举超时。若本轮未选出主节点,将进行下一轮选举(出现这种情况,是由于多个节点同时选举,所有节点均为获得过半选票)。
Candidate节点收到来自主节点的信息后,会立即终止选举过程,进入Follower角色。
为了避免陷入选主失败循环,每个节点未收到心跳发起选举的时间是一定范围内的随机值,这样能够避免2个节点同时发起选主。
3.2 Raft协议-日志复制
所谓日志复制,是指主节点将每次操作形成日志条目,并持久化到本地磁盘,然后通过网络IO发送给其他节点。其他节点根据日志的逻辑时钟(TERM)和日志编号(INDEX)来判断是否将该日志记录持久化到本地。当主节点收到包括自己在内超过半数节点成功返回,那么认为该日志是可提交的(committed),并将日志输入到状态机,将结果返回给客户端。
这里需要注意的是,每次选主都会形成一个唯一的TERM编号,相当于逻辑时钟。每一条日志都有全局唯一的编号。
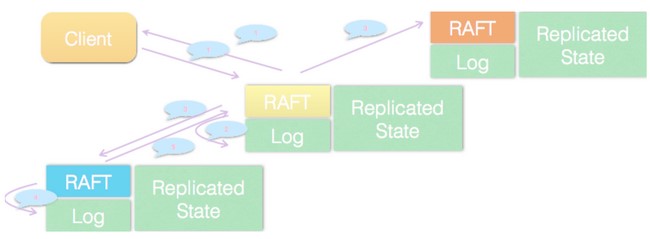
主节点通过网络IO向其他节点追加日志。若某节点收到日志追加的消息,首先判断该日志的TERM是否过期,以及该日志条目的INDEX是否比当前以及提交的日志的INDEX跟早。若已过期,或者比提交的日志更早,那么就拒绝追加,并返回该节点当前的已提交的日志的编号。否则,将日志追加,并返回成功。
当主节点收到其他节点关于日志追加的回复后,若发现有拒绝,则根据该节点返回的已提交日志编号,发生其编号下一条日志。
主节点像其他节点同步日志,还作了拥塞控制。具体地说,主节点发现日志复制的目标节点拒绝了某次日志追加消息,将进入日志探测阶段,一条一条发送日志,直到目标节点接受日志,然后进入快速复制阶段,可进行批量日志追加。
按照日志复制的逻辑,我们可以看到,集群中慢节点不影响整个集群的性能。另外一个特点是,数据只从主节点复制到Follower节点,这样大大简化了逻辑流程。
3.3 Raft协议-安全性
截止此刻,选主以及日志复制并不能保证节点间数据一致。试想,当一个某个节点挂掉了,一段时间后再次重启,并当选为主节点。而在其挂掉这段时间内,集群若有超过半数节点存活,集群会正常工作,那么会有日志提交。这些提交的日志无法传递给挂掉的节点。当挂掉的节点再次当选主节点,它将缺失部分已提交的日志。在这样场景下,按Raft协议,它将自己日志复制给其他节点,会将集群已经提交的日志给覆盖掉。
这显然是不可接受的。
其他协议解决这个问题的办法是,新当选的主节点会询问其他节点,和自己数据对比,确定出集群已提交数据,然后将缺失的数据同步过来。这个方案有明显缺陷,增加了集群恢复服务的时间(集群在选举阶段不可服务),并且增加了协议的复杂度。
Raft解决的办法是,在选主逻辑中,对能够成为主的节点加以限制,确保选出的节点已定包含了集群已经提交的所有日志。如果新选出的主节点已经包含了集群所有提交的日志,那就不需要从和其他节点比对数据了。简化了流程,缩短了集群恢复服务的时间。
这里存在一个问题,加以这样限制之后,还能否选出主呢?答案是:只要仍然有超过半数节点存活,这样的主一定能够选出。因为已经提交的日志必然被集群中超过半数节点持久化,显然前一个主节点提交的最后一条日志也被集群中大部分节点持久化。当主节点挂掉后,集群中仍有大部分节点存活,那这存活的节点中一定存在一个节点包含了已经提交的日志了。
至此,关于Raft协议的简介就全部结束了。
四、etcd 数据存储
etcd 的存储分为 内存存储 和 持久化(硬盘)存储 两部分。
内存中的存储除了顺序化的记录下所有用户对节点数据变更的记录外,还会对用户数据进行索引、建堆等方便查询的操作。
而持久化则使用预写式日志(WAL:Write Ahead Log)进行记录存储。
在 WAL 的体系中,所有的数据在提交之前都会进行日志记录。在 etcd 的持久化存储目录中,有两个子目录。一个是 WAL,存储着所有事务的变化记 录;另一个则是 snapshot,用于存储某一个时刻 etcd 所有目录的数据。通过 WAL 和 snapshot 相结合的方式,etcd 可以有效的进行数据存储和节点故障恢复等操作。
既然有了 WAL 实时存储了所有的变更,为什么还需要 snapshot 呢?随着使用量的增加,WAL 存储的数据会暴增,为了防止磁盘很快就爆满,etcd 默认每 10000 条记录做一次 snapshot,经过 snapshot 以后的 WAL 文件就可以删除。而通过 API 可以查询的历史 etcd 操作默认为 1000 条。
首次启动时,etcd 会把启动的配置信息存储到data-dir参数指定的数据目录中。配置信息包括本地节点的 ID、集群 ID 和初始时集群信息。用户需要避免 etcd 从一个过期的数据目录中重新启动,因为使用过期的数据目录启动的节点会与集群中的其他节点产生不一致(如: 之前已经记录并同意 Leader 节点存储某个信息,重启后又向 Leader 节点申请这个信息)。所以,为了最大化集群的安全性,一旦有任何数据损坏或丢失 的可能性,你就应该把这个节点从集群中移除,然后加入一个不带数据目录的新节点。
#@ etcd在磁盘中存储snapshot和WAL
[root@c7-Host ~]# tree /var/lib/etcd/infra11.etcd/
/var/lib/etcd/infra11.etcd/
└── member
├── snap
│ ├── 00000000000002db-000000000021447a.snap
│ ├── 00000000000002db-0000000000216b8b.snap
│ ├── 00000000000002db-000000000021929c.snap
│ ├── 00000000000002db-000000000021b9ad.snap
│ ├── 00000000000002db-000000000021e0be.snap
│ └── db
└── wal
├── 0000000000000000-0000000000000000.wal
├── 0000000000000001-000000000007ab55.wal
├── 0000000000000002-00000000000f53fd.wal
├── 0000000000000003-000000000016fc8c.wal
├── 0000000000000004-00000000001ea52c.wal
└── 0.tmp
3 directories, 12 files五、部署etcd
etcd 一般部署集群推荐奇数个节点,推荐的数量为 3、5 或者 7 个节点构成一个集群。
etcd安装很简单,直接从github下载,无需编译,或者yum安装都可以
#@yum install from epel
# yum install etcd -y
# etcd --version
etcd Version: 3.2.9
Git SHA: f1d7dd8
Go Version: go1.8.3
Go OS/Arch: linux/amd64Etcd 3.X的版本没有配置文件,也不能指定配置文件,所有选项都可以使用命令行参数或者环境变量来传递。
所以在CentOS7中直接编辑启动脚本就可以了。
# cat /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
User=etcd
# set GOMAXPROCS to number of processors
ExecStart=/bin/bash -c "GOMAXPROCS=$(nproc) /usr/bin/etcd \
--name infra1 \
--listen-peer-urls http://10.140.100.12:2380 \
--listen-client-urls http://10.140.100.12:2379,http://127.0.0.1:2379 \
--initial-advertise-peer-urls http://10.140.100.12:2380 \
--advertise-client-urls http://10.140.100.12:2379 \
--initial-cluster-token etcd-cluster \
--initial-cluster-state new \
--initial-cluster infra1=http://10.140.100.12:2380,infra2=http://10.140.100.13:2380,infra3=http://10.140.100.15:2380 \
--data-dir=/var/lib/etcd/ "
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target我们可以使用etcdctl命令检测etcd集群健康状况
[root@idc-sm-rd-k8s-1 ~]# etcdctl cluster-health
member 27683ef1237cf56 is healthy: got healthy result from http://10.140.100.15:2379
member 2ce5820bdb490d73 is healthy: got healthy result from http://10.140.100.13:2379
member 534827736701c1b8 is healthy: got healthy result from http://10.140.100.12:2379
cluster is healthy
[root@idc-sm-rd-k8s-1 ~]#
[root@idc-sm-rd-k8s-1 ~]# etcdctl member list
27683ef1237cf56: name=infra3 peerURLs=http://10.140.100.15:2380 clientURLs=http://10.140.100.15:2379 isLeader=false
2ce5820bdb490d73: name=infra2 peerURLs=http://10.140.100.13:2380 clientURLs=http://10.140.100.13:2379 isLeader=false
534827736701c1b8: name=infra1 peerURLs=http://10.140.100.12:2380 clientURLs=http://10.140.100.12:2379 isLeader=true
[root@idc-sm-rd-k8s-1 ~]#
[root@idc-sm-rd-k8s-1 ~]#etcdctl set /foo/bar "hello world"
hello world
[root@idc-sm-rd-k8s-1 ~]# etcdctl get /foo/bar
hello world
[root@idc-sm-rd-k8s-1 ~]# etcdctl ls /foo
/foo/bar
[root@idc-sm-rd-k8s-1 ~]#
参考资料
http://jolestar.com/etcd-architecture/
https://yeasy.gitbooks.io/docker_practice/content/etcd/intro.html
http://www.cnblogs.com/softidea/p/6517959.html
http://blog.mallux.me/2017/02/08/etcd/
http://blog.csdn.net/huwh_/article/details/74502762
转载请注明:IPCPU-网络之路 » Etcd简介、架构和工作原理