一、概述
Pandas是基于Python语言的一个数据分析库,初期主要由WesMcKinney先生在2008开发推出,并于2009年开源。该工具的设计之初是用于金融数据的分析处理,所以在基于时间序列的分析功能尤为强大。Pandas的名称PanelData(面板数据)和DataAnalysis(数据分析)的结合体,当然在中国,解释成国宝大熊猫也是大家的共识了。
pandas模块基于NumPy模块,在某种程度上可以把pandas看成Python版的Excel。
与NumPy模块相比,pandas模块更擅长处理二维数据,其主要有Series和DataFrame两种数据结构。
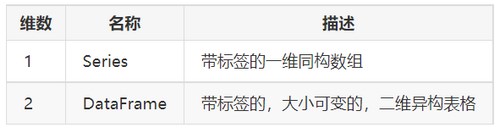
二、Series数据结构
Series类似于通过NumPy模块创建的一维数组,不同的是Series对象不仅包含数值,还包含一组索引,演示代码如下
>>> s = pd.Series(['丁一', '王二', '张三'])>>> print(s)
0 丁一
1 王二
2 张三
dtype: object可以看到,s是一个一维数据结构,并且每个元素都有一个可以用来定位的行索引,例如,可以通过s[1]定位到第2个元素'王二'。
Series很少单独使用,我们学习pandas模块主要是为了使用它提供的DataFrame数据结构。后面我们主要以DataFrame为主要对象进行学习和讨论。
三、DataFrame数据结构
DataFrame 是 Pandas 定义的一个二维数据结构。
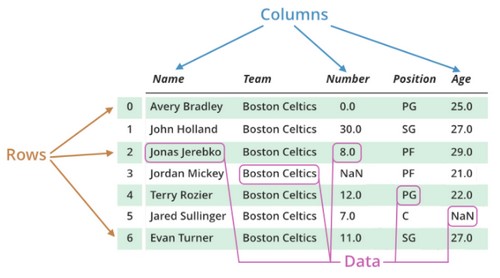
DataFrame可以通过Python的字典、列表等拥有类二维表结构的数据生成,如下
lst = ['Geeks', 'For', 'Geeks']
df1 = pd.DataFrame(lst)
#生成的DataFrame只三行一列
lst2 = [['Geeks', 'For', 'Geeks']]
df2 = pd.DataFrame(lst2)
#生成的DataFrame有一行三列
b = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=['date', 'score'], index=['A', 'B', 'C'])
dict = {'Name': ['Tom', 'nick', 'krish', 'jack'],
'Age': [20, 21, 19, 18]}
df3 = pd.DataFrame(dict)也可以通过载入csv、Excel等外部数据生成DataFrame
# making data frame from csv file
df3 = pd.read_csv("nba.csv", index_col ="Name")
# making data frame from Excel file
df4 = pd.read_excel('./billing.xlsx', sheet_name=0)
# making data frame from Json data
json = '''{"columns":["col 1","col 2"],
"index":["row 1","row 2"],
"data":[["a","b"],["c","d"]]}
'''
df5 = pd.read_json(json)既然pandas可以很容易的实现外部文件格式的读取,那么是不是同样也可以把数据输出到外部的CSV、Excel文件。当然可以。这部分功能我们后面讨论。
四、DataFrame的访问、选取DataFrame中的数据
对于一个DataFrame我们最先应该知晓他的行索引和列索引,然后才能选取数据,
语文 数学 英语
张三 34 67 87
李四 68 98 58
王五 75 73 86
#打印行索引
print(mydata.index)
Index(['张三', '李四', '王五'], dtype='object')
#@ 一般需要输入list格式的index
>>> print(list(mydata.index))
>>> print(mydata.index.values.tolist())
>>> print(mydata._stat_axis.values.tolist())
#打印列索引
>>> print(list(mydata))
['语文', '数学', '英语']
>>> print(mydata.columns.values.tolist())选取DataFrame中的数据
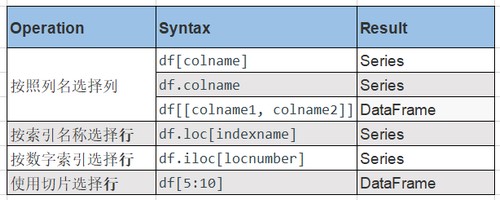
mydata['语文'] #选取语文一列,结果是Series
print(mydata.数学) #选取语文一列,结果是Series
mydata[['语文']] #选取语文一列,结果是DataFrame
mydata[['语文', '数学']] #选取语文、数学两列,结果是DataFrame
print(mydata.loc['李四']) # 抽取李四一行,输出Series
print(mydata.iloc[2]) # 抽取第三行,输出Series
print(mydata.iloc[0:1]) #抽取第一行
print(mydata.iloc[1:3]) #抽取第二行和第三行我们看到上面的这些方法只能选取行或者列的数据,用起来也不方便。其实我们最常用的是下面这几种:

print(mydata.loc['张三', '数学']) #取出张三数学成绩
print(mydata.loc['张三': '李四', '数学':'英语']) #取出从张三到李四的行,从数学到英语的列
print(mydata.iloc[0:1]) #抽取第一行
print(mydata.iloc[:, 0:1]) #抽取第一列
print(mydata.iloc[:, 2:3]) #选取所有行,只取第三列
print(mydata.iloc[0:2, [0, 2]]) #取出前两行,第一列和第三列
#当选取范围精确到一个值,输出的是单元格数据,否则输出的是Dataframe
print(mydata.at['李四', '英语']) # 输出李四英语分数
print(mydata.iat[1, 2]) #输出第二行第三列内容
print(mydata[mydata.数学 > 90 ])
# iloc特别注意的地方:
#用法是iloc[a:b , c:d] 这样输出的是DataFrame,iloc[: , a] 输出Series
print(mydata.iloc[:, 0:1]) #这个输出结果是DataFrame
print(mydata.iloc[:, 0]) #这个输出结果是Series注意:loc、at只能通过选取列标签索引数据,iloc、iat只能通过选取列位置编号(0,1,2,3)索引数据。另外之前还有一个ix方法,即可用编号也可以用标签,在0.20以后删掉了。
五、DataFrame列名的添加和修改
通过上面的学习,我们意识到index可能会自动生成,但是列名如果不指定的话,后面调用起来会比较麻烦,因此我们总结了列名的常用方法。
# 增加列名
mydf.columns = ['第一列', '第二列', '第三列']
#增加行名
mydf.index = ['A', 'B', 'C']
#修改制定列的名字。替换列名
mydf.rename(columns={'第二列': '新的列名'}, inplace=True)六、DataFrame行索引和常规列的转换
行索引和常规列是个比较常用的转换。
语文 数学 英语
A 34 67 87
B 68 98 58
C 75 73 86
#将行索引 转换为常规列
>>> mydf.reset_index(inplace=True)
index 语文 数学 英语
0 A 34 67 87
1 B 68 98 58
2 C 75 73 86
#将常规列 转换为行索引
>>> mydf.set_index('index', inplace=True)
语文 数学 英语
index
A 34 67 87
B 68 98 58
C 75 73 86更常用的是将常规列中的时间列转换为index
#Time数据列为时间戳
mydata['Time'] = pd.to_datetime(mydata['Time'], unit='s')
mydata.set_index('Time', inplace=True)七、行与列的新增与删除
这项功能不怎么常用,代码如下
# 新增一列数据
address = ['Delhi', 'Bangalore', 'Chennai', 'Patna']
df['Address'] = address
# 新增一行数据,比较麻烦,我们先生成一个DataFrame,然后添加,如下
fruit_list = [['Orange', 34, 'Yes']]
df = pd.DataFrame(fruit_list, columns=['Name', 'Price', 'Stock'])
# 新增一行数据,使用loc
df.loc[1] = ['Mango', 4, 'No']
df.loc[2] = ['Apple', 14, 'Yes']
#新增一行数据,使用append({dict})
df = df.append({'Name': 'Banana', 'Price': 6, 'Stock': 'Yes'} , ignore_index=True)
#通过合并两个DataFrame来增加行
lst2 = [['Pear', 4, 'No']]
df2 = pd.DataFrame(lst2, columns=['Name', 'Price', 'Stock'])
dfnew = df1.append(df2, ignore_index=True)
# 根据columName删除列
data.drop(["Team", "Weight"], axis=1, inplace=True)
# 根据indexName 删除行
data.drop(["Avery Bradley", "John Holland", "R.J. Hunter",
"R.J. Hunter"], inplace=True)
# 删除行和列,根据的是axis,axis=1 表示列,axis=0 表示行,默认是0。参考资料
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.loc.html