MongoDB的副本集ReplSet.md
一、MongoDB简介
MongoDB是一个基于文档的分布式文件存储数据库,旨在提供可扩展的高性能数据存储解决方案。其高性能,易部署,易使用,存储方便的特点使其深受广大开发者喜爱。
二、MongoDB主要特性
高性能:单点压测TPS:10w+
高可用:由于网络问题、机器重启或其他问题导致主库不可用时,集群会触发选举以选出新的主节点继续提供服务
一致性:提供fsync,journal刷盘策略及{ w:
, j: true/false , wtimeout: n }写策略保证数据一致性。如果集群选举导致数据不一致时,待原主节点添加至集群时,多出来的数据将以BSON格式导出到rollback文件中,以保证数据一致性。 强压缩:支持snappy及zlib压缩模式,可提供2-7倍压缩比
分布式:基于文档的分布式数据存储系统,提供容量及读写扩展
文档化:基于json化的文档记录格式,字段自由增减,3.0后默认文档级别锁
三、部署架构
3.1 单点部署
所谓的单点就是仅起一个mongod进程提供服务。
特点:资源消耗最少,部署简单,管理方便,但故障恢复成本较高
3.2 主从模式
类似于MySQL数据库时广泛采用的模式,采用双机备份后主节点挂掉了后从节点可以接替主机继续服务。所以这种模式比单节点的要可靠得多。
MongoDB的主从复制是通过Oplog实现的。就是主节点中所有的写入操作都会记录到MongoDB Oplog中,然后从库会来主库一直拉取Oplog并应用到自己的数据库中。
MongoDB官方已经不建议使用主从模式了,替代方案是采用副本集的模式。
3.3 集群部署
多台服务器共同提供服务,以数据冗余的方式提供高可用的服务。常用的集群部署架构有以下两种:
3.4 副本集(replset set)
简单地说,副本集就是有自动故障恢复功能的主从集群。副本集具有多个副本保证了容错性,并且可以自动选举Master节点保障高可用。
副本集是一组包含相同数据的mongod服务,架构图如:
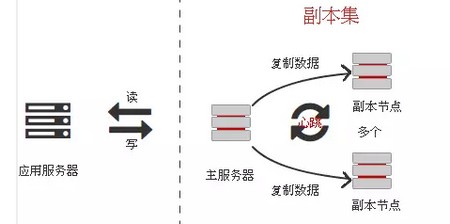
特点:资源消耗少,使用及后期运维方便
限制:集群的存储容量及TPS受限于单台服务器常见
3.5 分布式集群(monogs)(分片)
mongos是MongoDB提出的通过对数据和访问的水平拆分以应对大数据量和高吞吐量应用的数据存储系统的解决方案。通过对数据和访问的水平拆分以满足大数据量和高吞吐量的应用场景。架构图如:
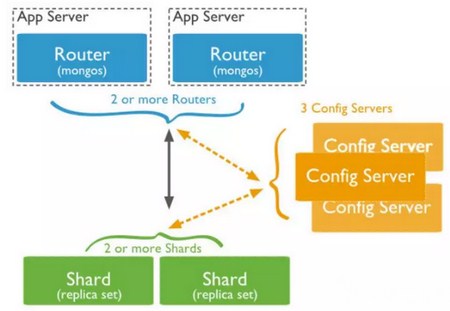
节点说明:
shard:每个shard保存集群的部分数据,合并后构成一份完整的数据集。线上环境中,Shard建议部署为一个副本集以提供数据冗余及高可用。
mongos:查询路由,将查询及更新操作路由至集群相应shard分片,并将执行结果反馈给用户或应用程序。
configserver:存储集群的元数据信息。3.2+开始,config服务器由镜像模式(SCCC)升级为副本集模式(CSRS),以利用标准的副本集的读取和写入协议处理分片的配置元数据,保证config的高可用及数据一致性。
特点:结构复杂、弹性扩展、弹性容量
本次只介绍副本集ReplSet的部署,分布式集群(分片)以后再讲。
四、副本集ReplSet的部署
准备三台服务器:192.168.1.101、192.168.1.102、192.168.1.103
分别安装并启动mongoDB服务。我这里使用了统一的配置文件,内容如下:
#start shell: numactl --interleave=all /usr/bin/mongod -f /etc/mongodb/mongodb.conf --journal
systemLog:
destination: file
path: "/data/logs/mongodb/mongodb.log"
quiet: true
logAppend: true
timeStampFormat: iso8601-utc
storage:
wiredTiger:
engineConfig:
cacheSizeGB: 6
dbPath: "/data/mongodb"
directoryPerDB: true
indexBuildRetry: false
# quota:
# enforced: false
# maxFilesPerDB: 8
syncPeriodSecs: 60
# repairPath: "/var/lib/mongo/_tmp"
journal:
enabled: false
# debugFlags: 1
# commitIntervalMs: 100
processManagement:
fork: true
pidFilePath: "/data/run/mongodb/mongod.pid"
net:
# bindIp: 127.0.0.1
port: 27017
# http:
# enabled: true
# RESTInterfaceEnabled: false
# ssl:
# mode: "requireSSL"
# PEMKeyFile: "/etc/ssl/mongodb.pem"
operationProfiling:
slowOpThresholdMs: 100
mode: "slowOp"
#security:
# keyFile: "/var/lib/mongo/mongodb-keyfile"
# clusterAuthMode: "keyFile"
# authorization: "disabled"
replication:
oplogSizeMB: 1024
replSetName: "replname"
secondaryIndexPrefetch: "all"然后,我们需要去初始化副本集。登陆其中1台Mongo中,执行
#设置replset服务器
config = { _id:"replname", members:[
... {_id:0,host:" 192.168.1.101:27017"},
... {_id:1,host:" 192.168.1.102:27017"},
... {_id:2,host:" 192.168.1.103:27017"}]
... }
#执行初始化
rs.initiate(config);完成以后,可以使用rs.status();查看当前mongodb所处的状态。
replname:PRIMARY> rs.status()
{
"name" : "192.168.1.101:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",对于rs.status();查看到的副本集状态,可以有如下情况:
PRIMARY : 主节点
SECONDARY : 备份节点
STARTUP : 刚加入到复制集中,配置还未加载
STARTUP2 : 配置已加载完,初始化状态
RECOVERING : 正在恢复,不适用读
ARBITER:仲裁者
DOWN : 节点不可到达
UNKNOWN : 未获取其他节点状态而不知是什么状态,一般发生在只有两个成员的架构,脑裂
REMOVED : 移除复制集
ROLLBACK : 数据回滚,在回滚结束时,转移到RECOVERING或SECONDARY状态
FATAL : 出错。查看日志grep "replSet FATAL"找出错原因,重新做同步
默认情况只允许主节点读写数据,副本节点不允许读,只要设置副本可以读即可。
在副本节点上执行:rs.slaveOk()
五、副本集的修改和管理
5.1 添加新成员
rs.add("server-3:27017");
rs.add( { host: "mongodb3.example.net:27017", priority: 0, votes: 0 } )
rs.add({_id: 3, host: "172.28.9.178:27017", priority: 0, votes: 0, hidden: true})
成员可以有以下属性
priority:表示一个成员被选举为Primary节点的优先级,默认值是1,取值范围是从0到100,将priority设置为0有特殊含义:Priority为0的成员永远不能成为Primary 节点。Replica Set中,Priority最高的成员,会优先被选举为Primary 节点,只要其满足条件。
hidden:将成员配置为隐藏成员,要求Priority 为0。Client不会向隐藏成员发送请求,因此隐藏成员不会收到Client的Request。
slaveDelay:单位是秒,将Secondary 成员配置为延迟备份节点,要求Priority 为0,表示该成员比Primary 成员滞后指定的时间,才能将Primary上进行的写操作同步到本地。为了数据读取的一致性,应将延迟备份节点的hidden设置为true,避免用户读取到明显滞后的数据。Delayed members maintain a copy of the data that reflects the state of the data at some time in the past.
votes:有效值是0或1,默认值是1,如果votes是1,表示该成员(voting member)有权限选举Primary 成员。在一个Replica Set中,最多有7个成员,其votes 属性的值是1。
arbiterOnly:表示该成员是仲裁者,arbiter的唯一作用是就是参与选举,其votes属性是1,arbiter不保存数据,也不会为client提供服务。
其中votes属性必须特别注意,因为选举primary,必须要求成员获得半数以上存活结点的votes通过。
如果添加hidden节点,其默认votes属性为1,在停机维护时如果出现1/2节点停机会出现严重的无法选举primary的问题,因此hidden节点votes属性最好设置为0,这样hidden节点停机不会影响集群的选举。
5.2 删除成员
rs.remove("SERVER-3:27017");在删除成员时会报错无法连接到数据库的信息,这是正常的,说明配置修改成功了。
重新配置副本集过程中的最后一步,主节点会关闭所有连接,因此shell会短暂断开然后重新自动建立连接。
5.3 配置副本集内容并重载
同样也可以修改config内容后进行重载
#载入配置
cfg = rs.conf()
#设置votes值
cfg.members[0].votes = 1
cfg.members[1].votes = 1
cfg.members[2].votes = 1
cfg.members[3].votes = 0
#重载
rs.reconfig(cfg)5.4 使主节点变成备份节点
rs.stepDown(time) 可以让主节点退成备份节点,timie单位是秒,默认60s。60s内主被副本集的其他成员获得,时间到后,会重新进行选举,一般都会重新成为主(优先级)。
5.5 阻止选举
rs.freeze(time)阻止选举,始终出于备份节点状态。比如主节点需要做一些维护,不希望其他成员选举为主节点,可以在每个备份节点上执行。强制他们出于备份节点状态。
5.6 监控复制延迟时间
在备库上运行以下命令
replname:SECONDARY>db.printSlaveReplicationInfo()
source: 192.168.1.101:27017
syncedTo:Mon Dec 01 2014 18:12:32 GMT+0800 (CST)
0secs (0 hrs) behind the primary
source: 192.168.1.102:27019
syncedTo: Mon Dec 01 2014 18:12:32 GMT+0800 (CST)
0 secs (0 hrs) behind the primary之所以有2个同步源,是因为启用了链式复制。
六、副本集的读写分离
主节点读写压力过大,如何解决呢?常见的解决方案是读写分离,MongoDB副本集的读写分离如何做呢?
Mongodb的客户端(驱动)支持5种复制集读选项:
primary:默认模式,所有的读操作都在复制集的 主节点 进行的。
primaryPreferred:在大多数情况时,读操作在 主节点 上进行,但是如果主节点不可用了,读操作就会转移到 从节点 上执行。
secondary:所有的读操作都在复制集的 从节点 上执行。
secondaryPreferred:在大多数情况下,读操作都是在 从节点 上进行的,但是当 从节点 不可用了,读操作会转移到 主节点 上进行。
nearest:读操作会在 复制集 中网络延时最小的节点上进行,与节点类型无关。
注意:实际生产使用中,会存在从节点上的数据可能不是最新数据的问题,需要根据业务情况决定读写分离。
七、副本集的回滚
我们知道在发生切换的时候是有可能造成数据丢失的,主要是因为主库宕机,但是新写入的数据还没有来得及同步到从库中,这个时候就会发生数据丢失的情况。
那针对这种情况,MongoDB增加了回滚的机制。在主库恢复后重新加入到复制集中,这个时候老主库会与同步源对比oplog信息,这时候分为以下两种情况:
1、 在同步源中没有找到比老主库新的oplog信息。
2、 同步源最新一条oplog信息跟老主库的optime和oplog的hash内容不同。
针对上述两种情况MongoDB会进行回滚,回滚的过程就是逆向对比oplog的信息,直到在老主库和同步源中找到对应的oplog,然后将这期间的oplog全部记录到rollback目录里的文件中,如果但是出现以下情况会终止回滚:
对比老主库的optime和同步源的optime,如果超过了30分钟,那么放弃回滚。
在回滚的过程中,如果发现单条oplog超过512M,则放弃回滚。
如果有dropDatabase操作,则放弃回滚。
最终生成的回滚记录超过300M,也会放弃回滚。
上述我们已经知道了MongoDB的回滚原理,但是我们在生产环境中怎么避免回滚操作呢,因为毕竟回滚操作很麻烦,而且针对有时序性的业务逻辑也是不可接受的。那MongoDB也提供了对应的方案,就是WriteConcern,可以设置数据保存进度,是确保进度保存到journal,还是落盘,还是Replica Acknowledged,有兴趣的朋友可以仔细了解。其实这也是在CAP中做出一个选择。
更详细的回滚资料,https://blog.csdn.net/jianlong727/article/details/73321905
八、特殊情况下集群成员的重新同步
因为某些原因,导致副本集中的从节点落后于主节点太多,跟不上主节点的步伐了,会导致这个节点一直处在RECOVERING状态。也就是官网文档所说的stale(陈旧的)。
在这种情况下,需要重新同步数据(initial sync)到该节点,官网提供了两种方式:
Automatically Sync a Member
停掉mongodb,清空数据目录,启动mongodb,让mongodb自动触发同步。这是个简单的方式,但是耗时较长。(要求oplog不能轮转,适用于数据库集群创建初期)Sync by Copying Data Files from Another Member
停掉mongodb,清空数据目录,从其他节点(需要停止mongod)拷贝数据,然后启动。拷贝来的数据时间上要求能跟上oplog。需要包含local目录。本方式操作步骤较多,但是最为快速。
查看OPlog方法:
shard1:SECONDARY> db.printReplicationInfo();
configured oplog size: 4096MB
log length start to end: 129346secs (35.93hrs)
oplog first event time: Tue Mar 22 2016 11:29:04 GMT+0800 (CST)
oplog last event time: Wed Mar 23 2016 23:24:50 GMT+0800 (CST)
now: Wed Mar 23 2016 23:24:50 GMT+0800 (CST)
shard1:SECONDARY>
#此例中,oplog大小为4G,保持了35个小时的数据官网相关文档,https://docs.mongodb.com/manual/tutorial/resync-replica-set-member/#replica-set-resync-by-copying
参考资料
http://www.cnblogs.com/lens/p/4833655.html
https://zhuanlan.zhihu.com/p/29530029
https://mp.weixin.qq.com/s/VuRCXWKgrP9Myp-3IptGhQ
http://www.mongoing.com/archives/5200
转载请注明:IPCPU-网络之路 » MongoDB副本集ReplSet