MongoDB备份汇总.md
一、概述
任何数据库的备份操作无疑都是DBA日常运维中重要的一部分,今天我们来总结下MongoDB备份的相关内容。
如同MySQL的全量备份、增量备份,MongoDB也可以实现全量备份、增量备份,我们先看下全量备份
二、全量备份
阿里云的大牛为我们总结的全量备份的方法
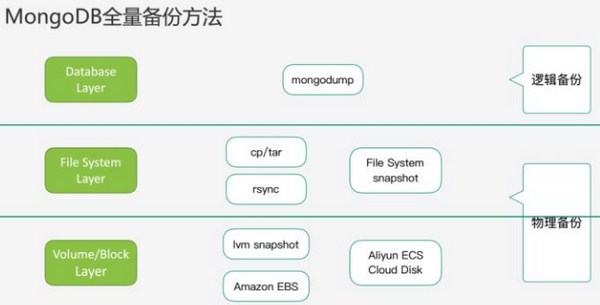
全量备份分为逻辑备份和物理备份。
逻辑备份就是通过mongodump和mongorestore两个工具在数据库层将MongoDB的数据进行导出和导入,这也是官方推荐的方式,mongodump会将数据导出为BSON格式,如果数据为索引时,只导出元数据,例如索引建在哪个字段上、什么类型的索引、索引有哪些选项这些元数据,并不会把索引的数据本身导出来。在数据恢复时通过insert方法重新将数据插回到数据库当中。在恢复的过程中需要重建索引,如果索引的数据量非常大,重建索引的过程将花费很长的时间。
逻辑备份适合数据量比较小的情况,比如几十G,不超过100G的情况,否则备份和恢复效率极低。
在使用mongodump时,有一个很重要的参数--oplog,它的作用是在导出的同时生成一个oplog.bson文件,存放在你开始进行dump到dump结束之间所有的oplog。使用mongorestore恢复时可以指定相应参数重放oplog。如下图,

物理备份通过某些手段将物理文件拷贝走进行备份,或者直接对文件系统磁盘进行快照,在恢复的过程中不需要重建索引,只需要将备份数据放置在原数据目录,或者恢复快照,相对全量逻辑备份更为高效。
物理备份好处是效率高,但不能针对单库单表进行备份和恢复,而且恢复时要求版本、引擎环境必须一致。在数据量较大的多数情况,我们推荐物理备份,如果你使用的阿里云、AWS等主机,优先推荐快照备份。
三、增量备份
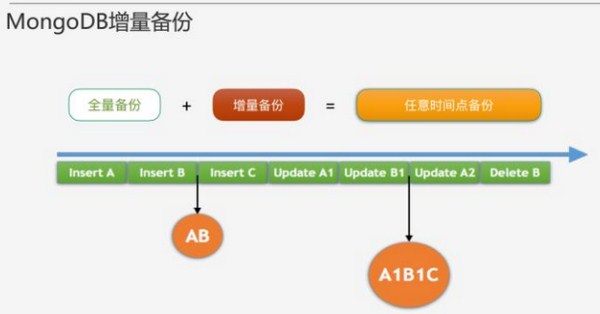
MongoDB副本集有oplog用来主备同步,增量备份就是对指定时间段的oplog进行dump,然后在某个全量备份基础上进行回放,原理和MySQLbinlog增量备份一致。
这里我们简单介绍下oplog的格式
{"ts":{"$timestamp":{"t":1541685325,"i":2}},"t":{"$numberLong":"11"},"h":{"$numberLong":"169245588685612356"},"v":2,"op":"u","ns":"iip_shard.qasprope
rties","o2":{"_id":{"$oid":"5be2647ff3e24f580d732aec"}},"o":{"$set":{"officialReadAt":{"$date":"2018-11-08T13:55:25.516Z"}}}}字段内容如下,
ts:操作发生时的时间戳,这个时间戳包含两部分内容t和i,t是标准的时间戳(自1970年1月1日 00:00:00 GMT 以来的毫秒数)而i是一个序号,目的是为了保证 t 与 i 组合出的 Mongo 时间戳 ts 可以唯一的确定一条操作记录
op:操作类型,插入对应i;更新对应u;删除对应d;但有一种情况是n,它表示无操作(no-op),紧紧代表一个消息信息。
ns:这个操作的库和collection的组合
o与o2:他们都是操作相关的数据内容
对于不同的版本的MongoDB,其oplog的格式也不一样,这点需要格外注意(此文使用的版本是3.4.0)。
了解了数据结构,我们可以执行dump导出相关的数据了,如下,
mongodump --port 27018 -d local -c oplog.rs -o dump --query "{ts : { \$gte : { \$timestamp : { t : 1519869600, i : 1 } }, \$lte : { \$timestamp : { t : 1519956000, i : 1 } } }} "TIPS:导出的bson文件可以使用命令bsondump oplog.rs.bson 转换成JSON格式。
理论我们说完了,接下来我们分别针对副本集ReplSet、分片Sharding+副本集两种常见的情况来说下备份恢复时需要注意的事项。
四、副本集ReplSet备份
我们推荐使用拷贝数据文件或者对磁盘进行快照的方式进行备份,为了避免对线上业务产生影响,一般会在secondary或者专门的备份节点上进行,拷贝数据之前,需要对数据进行锁定,以防止拷贝过程中的变化,
db.fsyncLock();通过打印oplog状态,可以拿到备份数据的时间戳。
db.printReplicationInfo();拷贝完成后,需要解锁
db.fsyncUnlock();五、分片Sharding+副本集的备份
MongoDB的分片集群由configserver副本集和多个shard副本集组成,同样备份时需要锁定文件,拷贝文件。但这里会存在一个比较棘手的问题,如何保障多个shard的备份数据是同一时间的呢?
这里目前来看只能通过oplog来追平了。即采用全量备份加增量备份可以做到各节点备份恢复至同一时间点,在备份结束比较早的节点可以多抓取一些oplog,备份结束比较晚的节点可以少抓取一些oplog,从而保证各自节点的备份加oplog能够对应到同一个时间点。
对于分片集群,还有一个地方需要注意,平衡器。
MongoDB的平衡器是一个后台进程,监视每个分片上块的数目。当给定分片上的块数达到特定的迁移阈值时,平衡器会尝试在分片之间自动迁移块,使得每个分片达到相等数量的块。平衡器将比较多块的分片中的块迁移到块数量较少的分片中。平衡器迁移块,直到集合在分片之间的块均匀分布。
在备份数据时,需要在mongos上关闭平衡器,以免对备份数据产生影响。
#关闭
sh.stopBalance();
#启动
sh.startBalancer();阿里云的专家给提示了另外一种办法,即给平衡器设置一个维护窗口(比如凌晨2:00关闭,6:00打开),在维护窗口内进行数据备份。
参考资料
http://wupher.farbox.com/post/mongodb-bei-fen-ce-lue
https://zhuanlan.zhihu.com/p/33419743
http://xbsura.com/2017/10/08/mongodb-backup-methods/ (中文)
https://docs.mongodb.com/manual/core/backups/ (英文)
https://www.cnblogs.com/yaoxing/p/mongodb-backup-rules.html
https://cloud.tencent.com/developer/article/1079157
https://github.com/Percona-Lab/mongodb_consistent_backup
转载请注明:IPCPU-网络之路 » MongoDB备份汇总